Обсудить
бизнес-задачи
бизнес-задачи

Особенности загрузки моделей в Analytic Workspace
блог о bi, №1 в рунете
Ранее в нашей статье “Разработка дашборда на BI-платформе Analytic Workspace” мы рассмотрели процесс разработки дашборда. В этой статье мы подробно рассмотрим, как логические модели загружаются во внутреннее хранилище AW BI и какие особенности важно учитывать.
Основу функционирования Analytic Workspace составляют модели – это создаваемые пользователем объекты, представляющие собой целевые таблицы на основе выборки и объединения данных из одного или нескольких источников или других моделей. В системе имеются два типа моделей :
Таблица 1 – Сравнение двух видов моделей
Поскольку live-модели не требуют дополнительной загрузки данных, основное внимание следует уделить процессу загрузки логических моделей, который включает следующие этапы:
- Сбор данных из источников;
- Преобразование в соответствии с заданными правилами;
- Загрузка в целевое хранилище AW BI (ClickHouse).
Указанные процессы конфигурируются и оркестрируются с использованием Apache AirFlow. Для мониторинга выполнения операций предусмотрена возможность ручного подключения к AirFlow. Для этого требуется перейти в режим редактирования модели и нажать на соответствующую кнопку “Посмотреть загрузку в AirFlow”

Рисунок 1 – Переход к интерфейсу AirFlow
В открывшемся окне можно наглядно увидеть задачи, соответствующие каждому этапу загрузки:
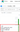
Рисунок 2 – Этапы загрузки модели в DAG в Airflow
Этапы загрузки
Рассмотрим каждый этап подробнее:
На первом этапе осуществляется подключение к используемому источнику данных, откуда данные сохраняются в файловое хранилище сервера в формате .parquet. Затем оттуда данные загружаются в S3-подобное хранилище данных MinIO. Оно используется как промежуточное хранилище на время загрузки в целевое хранилище.
ETL-обработка на втором этапе выполняется с использованием Apache Spark. Он напрямую подключается к хранилищу MinIO и выполняет настроенною пользователем ETL обработку. В конфигурационном файле AW BI указаны параметры для прямого подключения к консоли Spark Master. С ее помощью можно анализировать выполняемые процессы.

Рисунок 3 – Интерфейс Spark Master
В результате обработки формируется набор уже обработанных данных, который также сохраняется в хранилище. На этом этапе необходимо учесть, что временно на сервере используется примерно в 2 раза больше дискового пространства, чем занимает итоговая модель, так как в момент обработки данных Spark-ом одновременно хранятся исходные данные, и обработанные.
Финальный этап предполагает загрузку обработанных данных в ClickHouse с последующей очисткой промежуточных файлов. Обратите внимание, что в конфигурационном файле системы по умолчанию установлен параметр MODEL_SYNC_COUNT = 2 (количество сохраняемых экземпляров модели), который может быть скорректирован при необходимости.

Рисунок 4 – Модели в БД ClickHouse
Следует отметить, что обработка крупных моделей создаёт значительную нагрузку на дисковую подсистему, что может привести к исчерпанию ресурсов сервера.
Таким образом, из всех подключенных источников данных, получается единая таблица в ClickHouse, которая содержит все обработанные данные логической модели.
Практические советы
- Spark специально предназначен для быстрой обработки больших объемов данных, следовательно рекомендуется настраивать ETL обработку именно в AW, а не напрямую в используемых источниках. Тестирование показало, что ETL-обработка на стороне источника данных, а конкретно на стороне SQL Server, занимает примерно в 6 раз больше времени, чем аналогичная обработка с помощью Spark.
- В процессе загрузки данных модель может занимать достаточно много дискового пространства сервера. В связи с этим можно снизить пиковую нагрузку на память следующим образом: загрузить данные частями, а затем вручную, подключившись к ClickHouse объединить обработанные данные нескольких частей (таблиц). Например, если необходимо загрузить данные о продажах за год (предположим, что они занимают X Гб), но количество свободной памяти не позволяет это сделать загрузкой одной большой модели (если на сервере свободной памяти больше, чем X Гб, но меньше, чем 2X Гб). В таком случае, можно временно сделать две модели по полгода, загрузить их в хранилище, а затем вручную (с помощью команды INSERT) добавить записи из одной таблицы в другую. Таким образом получим весь объем данных в одной модели, избежав при этом чрезмерной нагрузки на память сервера, связанной с особенностями ETL-обработки.
- Стоит отметить, что в AW BI есть встроенный функционал инкрементальной загрузки (данные из источника загружаются не полностью, а по частям). Однако данный подход не позволит избежать пиковой нагрузки на дисковое пространство сервера, которая возникает при ETL-обработке, так как Spark будет обрабатывать весь объем данных целиком.
Выводы
- Логические модели обеспечивают гибкость и централизованную обработку данных;
- При проектировании модели стоит учитывать объем данных и доступные ресурсы сервера, особенно при работе с большим количеством записей;
- Использование Spark обеспечивает эффективную обработку больших объемов данных.
Грамотное проектирование модели в AW BI позволяет уменьшить время загрузки данных модели, а также более эффективно использовать ресурсы сервера.